baumhaus.digital/Art, Cognition, Education/Human and Machine Learning/Supervised learning/Features/Feature selection
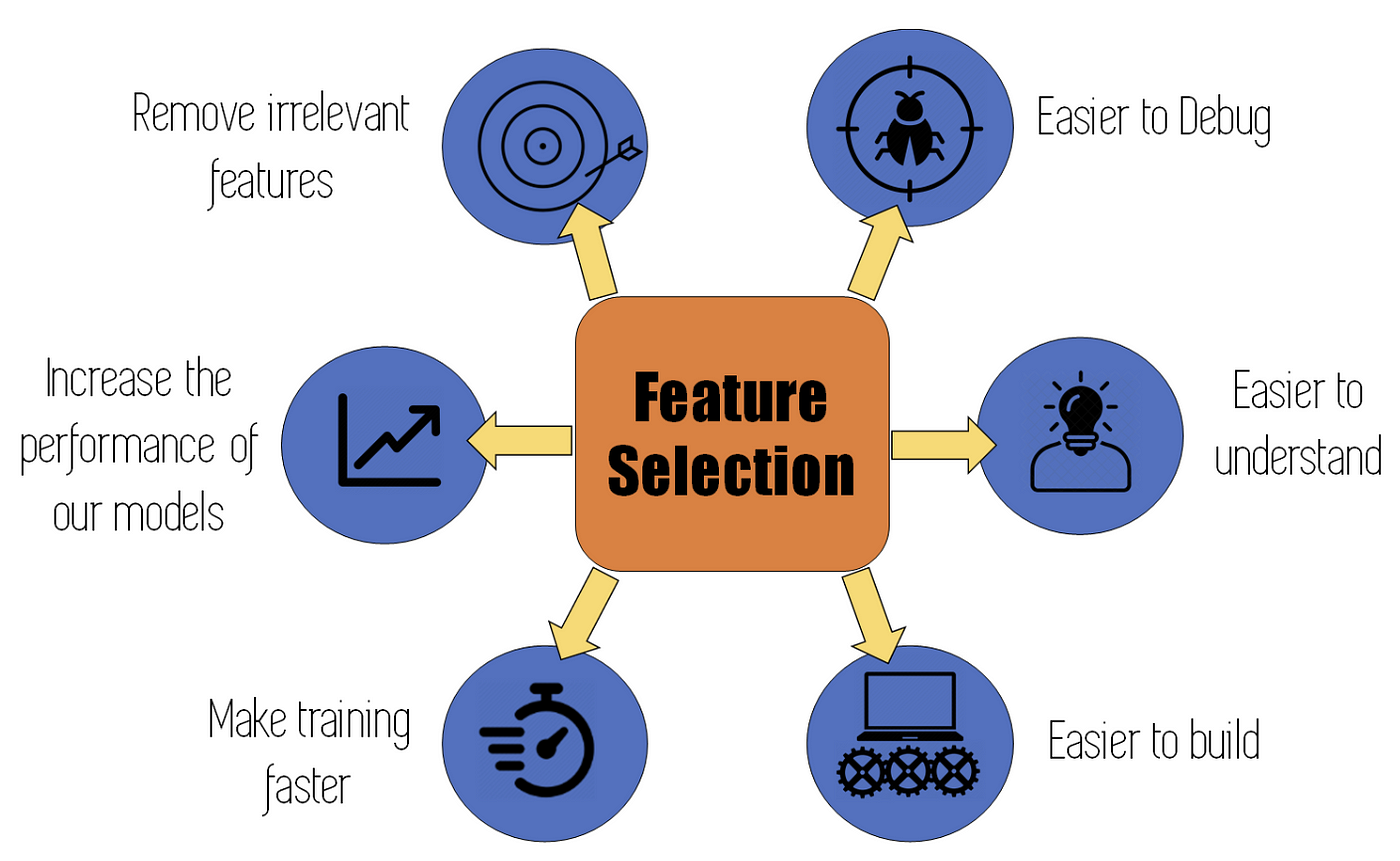
Feature selection involves choosing the most relevant features from a dataset to improve model accuracy, reduce overfitting, and enhance computational efficiency. Techniques include filters (e.g., chi-square tests), wrappers (e.g., recursive feature elimination), and embedded methods like LASSO. Boosting algorithms (e.g., AdaBoost, Gradient Boosting, XGBoost) also inherently perform feature selection by iteratively focusing on features with the highest predictive power.
Feature selection process is crucial in high-dimensional datasets, enabling models to concentrate on the most impactful data while discarding irrelevant or redundant features.
0 Axones
[Impressum, Datenschutz, Login] Other subprojects of wizzion.com linkring:
giver.eu
gardens.digital
teacher.solar
baumhaus.digital
puerto.life
fibel.digital
refused.science
naadam.info
udk.ai
kyberia.de